Le pipeline est une technique implémentée dans un processeur pour optimiser le temps de traitement d'une instruction. En clair il repose sur le principe simple de la chaîne de montage, pour produire plusieurs fois à la suite des objets on peut faire chaque objet d'un coup, un à la suite. Le temps total sera donc le nombre d'objet multiplié par le temps mis pour un seul objet.
Maintenant l'idée est de découper la fabrication de l'objet en plusieurs étapes ou "étages" indépendants, de telle sorte que chaque étage peut fonctionner en même temps que tous les autres et qu'il soit nécessaire de passer par tous les étages inférieurs pour atteindre un étage donné.
Ainsi imaginons un pipeline à 3 étages et 3 objets à concevoir et supposons que le temps mis à chaque étage soit le même : T. L'objet 1 arrive au premier étage du pipeline, pendant ce temps les deux autres objets attendent, une fois l'étape 1 passée, l'objet 1 passe à l'étage 2, libérant ainsi l'étage 1, l'objet 2 est donc placé à l'étage 1, l'objet 3 attend. Ensuite une fois l'étape 2 de l'objet 1 et l'étape 1 de l'objet 2 finies, l'objet 1 passe à l'étage 3, l'objet 2 à l'étage 2 et l'objet 3 à l'étage 1 qui vient d'être libéré. Et ainsi de suite...
Le temps total mis sans pipeline serait par exemple de 3 * 3T soit 9T. Avec pipeline il est seulement de 5T !
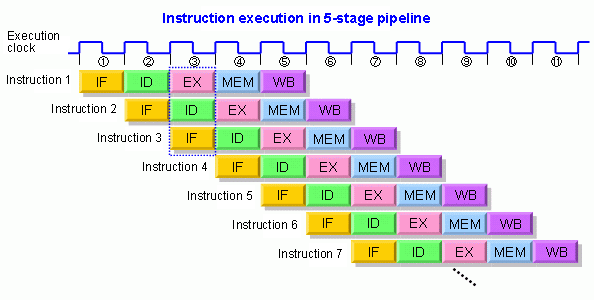
L'idée est la même pour le pipeline du CPU, chaque instruction à exécuter est séparée en étages mettant sur ce schéma un cycle d'horloge à être exécutée. Les étapes sont les suivantes le "fetch" (IF pour "Instruction Fetch") qui sépare la commande et les opérandes, le décode (ID pour "Instruction Decode") qui permet de traduire la commande pour la rendre intelligible par les unités du processeur, l'exécution à proprement dit de l'instruction (EX), MEM (Memory) correspond aux opérations post-exécution qui sont exécutées dans la mémoire, par exemple écrire à un certain endroit ou lire une donnée, et enfin le "Write-Back" (WB) finalise l'instruction en mettant à jour les registres avec les résultats.
Ce type de pipeline synchronisé par le front d'horloge du CPU est appelé "pipeline synchrone", il existe un autre type de pipeline appelé "asynchrone" où la mise à jour et les changements d'étages sont effectués via la communication entre les étages.
Le nombre d'étages du pipeline est caractéristique du CPU et est appelé "profondeur du pipeline", la profondeur des pipelines des processeurs modernes est souvent entre 12 et 15 étapes, qui sont des découpages des étapes présentées (fetch, decode..)
